随着科技技术的不断演进,数字化已成为各行业内一个非常重要且极具吸引力的市场,其目标是将IT技术与产品、系统、解决方案和服务进行融合,贯穿于从研发设计到生产到技术维护的整个产业链。

乘着数字化这股智慧东风一逐渐吹进了万千行业,矿山就是其中的一个典型领域。从矿山自动化到数字矿山,再到如今的智慧矿山,数字经济时代,有关未来矿山建设与实现方式不断被刷新。当下,智慧矿山利用底层传感器实现数据采集,物联网(IoT)释放数据威力,从生产运营、成本管控、采购销售等系统,整合所有数据通过精准分析,为煤炭企业决策层提供精准、实时的数据支撑,实现降低成本、提高决策效率的目标。
亿信华辰PetaBase实时大数据平台,基于Hadoop架构,集成了生态圈中的主流热门组件并不断的进行相关功能的优化。可对矿山生产大数据、销售大数据、物流大数据、设备运行大数据、安全大数据、环保大数据等的进行智慧采集与存储,助其最终落地大数据分析应用。
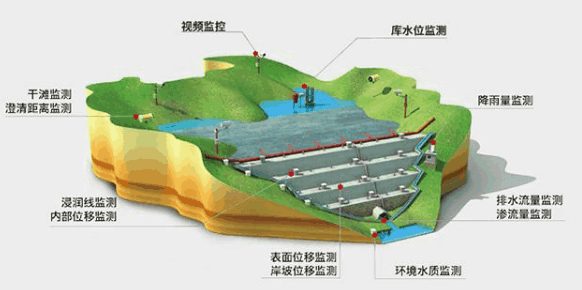
智能采集应对煤矿多数据之难
PetaBase可进行多源数据采集,支持OPC、MQTT等多种传输协议,可实现物联网、电子交易等结构化、半结构化、非结构化数据的统一接入。
OPC数据或时序数据库
该类数据通常为煤矿的设备数据等,记录了各个测点当前的实时值,通过java接口的方式读取数据,存储到PeteBase的kudu当中作为底层存储,数据管理通过impala搜索引擎进行。
TXT文件数据
该类数据通常为安全监测、人员定位、水文、微震、束管数据、应力数据等,该类数据反映了生产和人员信息的数据,会几秒钟或几分钟生成一个个TXT文件的形式,可以使用Flume收集数据,Kafka消息队列缓存数据为不同主题,将不同主题的数据通过Streamsets数据集成、数据加工工具,存储到PeteBase的kudu当中作为底层存储,数据管理通过impala搜索引擎进行。
关系型数据库数据
该类数据为一些业务系统产生的数据,为财务、销售、采购等数据,通常保存在业务系统自身的数据库当中,为了统一分析将数据也一并抽取到PeteBase的kudu当中。
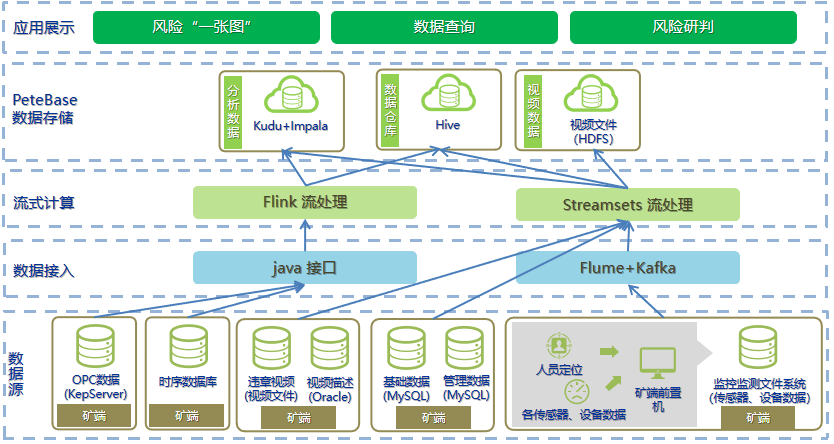
一体化存储应对量级之大
矿业对于数据的处理要求,集中在设备数据、安全监测、人员定位、水文、应力、振动等方面。首先,矿山监控的数据都是大量带有时间戳的数值,本身结构简单,也没有太多关联性的查询需求;其次,按设备、按时间段回溯和统计分析是最主要的应用场景。传统关系型数据库已无法对此类数据进行管理,PetaBase旨在数据存储和数据分析两个层面实现对矿山数据的统一管控。
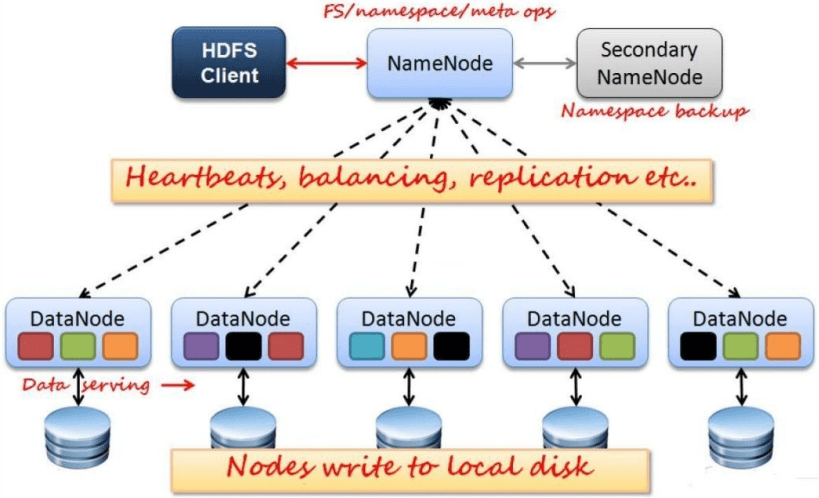
PeteBase最少需要3台服务器来进行集群部署,将多台服务器的资源整合为一个称之为HDFS的分布式文件系统内,该系统集成了所管理节点的所有硬盘资源,但有数据写入时根据一系列负载均衡算法,自动将数据按规定拆分分别存储在各个服务器上,利用了低廉的服务器来进行海量数据的存储,可以横向对硬盘扩容(增加服务器个数),而非之前的纵向扩容(增加单个服务器的存储空间),当存储量不足时可以通过新增服务器来满足数据存储的需求。
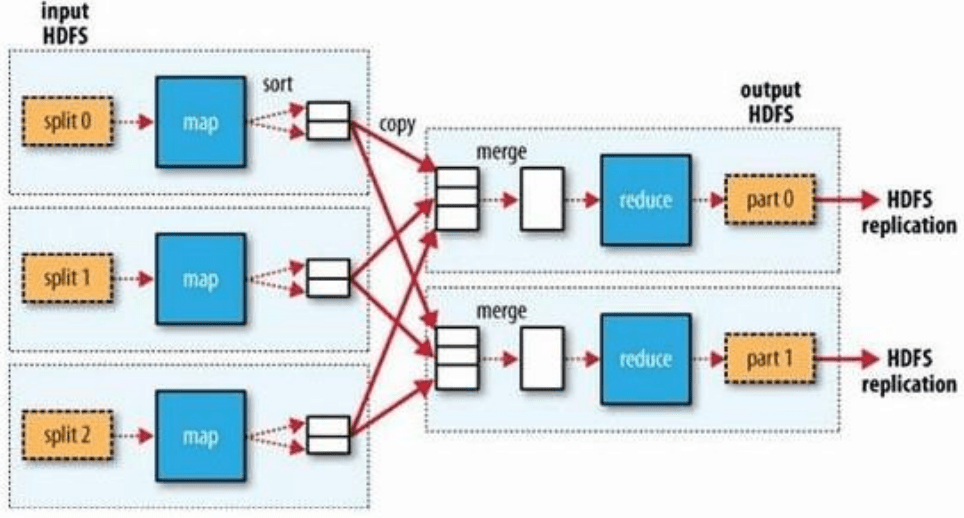
PeteBase的计算也是采用了多台服务器的内存一起参与了计算,大量数据的计算速度就会明显的高于传统数据库,单台服务器的计算速度,其核心的设计思想为分而治之,单个人做不完的活来进行团队合作完成。将大批量数据,分布的放在各个服务器当中,各个服务器上计算自己所存的数据,然后将数据进行汇总,完成对海量数据的运算分析。
对于矿山生产系统而言,安全是第一位的,生产状况是第二位的,矿端各系统存储的历史数据的分析,在此就显都尤为重要,数据的价值是无价的,利用这些数据的趋势走向就可以预判出设备情况进行提前预警,观察人员作业情况方便了解井下实时动态等,古有秀才不出门全知天下事,现有了PeteBase对数据的管理,可以做到人在集团中,随时一手掌握矿山的方方面面。
PetaBase在获取、存储、管理、分析方数据面大大超出了传统数据库软件,可以实现海量的非结构化/半结构化/结构化数据管理,同时进行离线批处理计算和流式计算处理。满足高吞吐、大数据量和低时延实时处理等多方面的数据计算要求,具有灵活性、集成性、安全性、扩展性、高可用性、兼容性等特性,可为矿山企业的数据管理、数据建设、数据分析保驾护航。